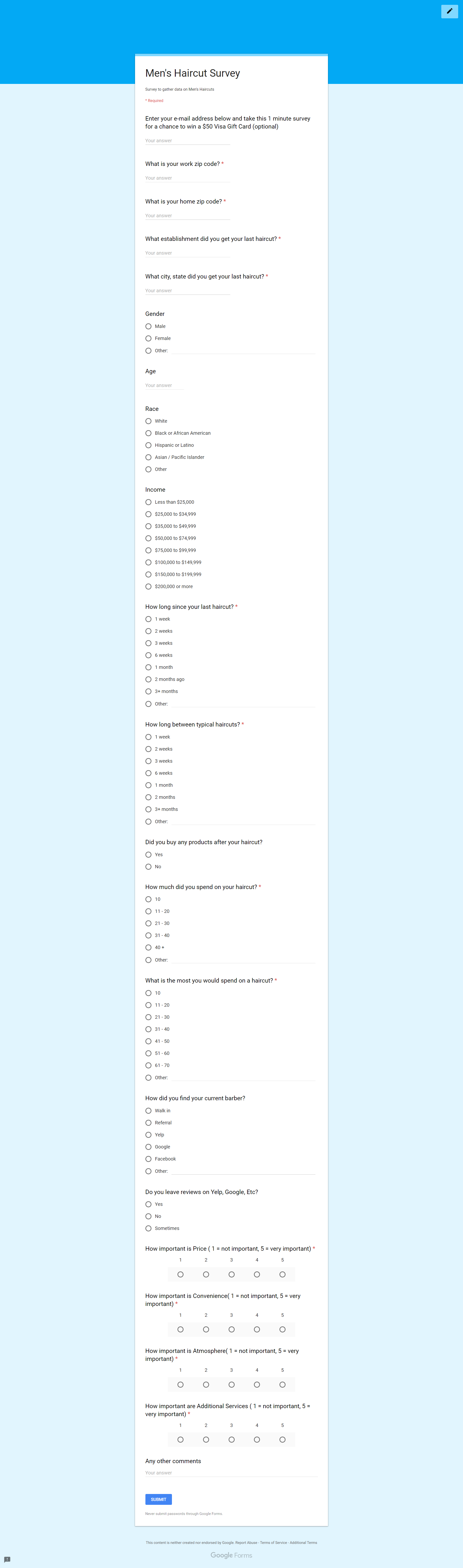
This code reads in the responses from the Google Forms Survey below. The survey responses are exported in CSV format.
The numeric_survey function below takes the responses and converts them to numeric values. This allows us to perform calculations on the responses to find correlations and create a GLM.
Google Forms Survey¶
In [2]:
# dependencies
import pandas as pd
import numpy as np
In [3]:
# import googlespreadsheet from survey
googlecsv = pd.read_csv('../data/survey041718.csv')
In [7]:
# numeric scale legends
# gender numeric legend
gender_scale = pd.DataFrame({
'gender':['Male','Female','Other',''],
'gender_values':['1','0','2','3']
})
gender_scale
#gender_scale.to_csv('gender_scale.csv',index=False)
# race numeric legend
race_scale = pd.DataFrame({
'race':['Asian / Pacific Islander',
'Black or African American',
'Hispanic or Latino',
'White',
'Other',''
],
'race_values':[1,2,3,4,5,0]
})
race_scale
#race_scale.to_csv('race_scale.csv',index=False)
#income numeric legend
income_scale = pd.DataFrame({
'income':['','Less than $25,000',
'$25,000 to $34,999',
'$35,000 to $49,999',
'$50,000 to $74,999',
'$75,000 to $99,999',
'$100,000 to $149,999',
'$150,000 to $199,999',
'$200,000 or more'
], 'income_values':[0,1,2,3,4,5,6,7,8]})
income_scale
#income_scale.to_csv('income_scale.csv',index=False)
# days since last haircut numeric legend
days_last_scale = pd.DataFrame({
'days_last_haircut':['','1 week',
'2 weeks',
'3 weeks',
'1 month',
'2 months ago',
'6 weeks',
'3+ months',
'other'
],'days_last_values':[0,1,2,3,4,5,6,7,8]
})
days_last_scale
#days_last_scale.to_csv('days_last_scale.csv',index=False)
# time between haircuts numeric legend
time_between_scale = pd.DataFrame({
'time_between_haircut':['','1 week',
'2 weeks',
'3 weeks',
'1 month',
'2 months ago',
'6 weeks',
'3+ months',
'other'
],'time_between_values':[0,1,2,3,4,5,6,7,8]
})
time_between_scale
#time_between_scale.to_csv('time_between_scale.csv',index=False)
# purchased products numeric legend
products_scale = pd.DataFrame({
'products':['Yes','No'],
'products_values':[1,0]
})
products_scale
#products_scale.to_csv('products_scale.csv',index=False)
# how much spent numeric scale
spend_scale = pd.DataFrame({
'did_spend':['','10',
'11 - 20',
'21 - 30',
'31 - 40',
'40 +',
'other',
],
'spend_values':[0,1,2,3,4,5,6]
})
spend_scale
#spend_scale.to_csv('spend_scale.csv',index=False)
# max spend numeric scale
max_spend_scale = pd.DataFrame({
'max_spend':['','10',
'11 - 20',
'21 - 30',
'31 - 40',
'41 - 50',
'51 - 60',
'61 - 70',
'other'
],
'max_spend_values':[0,1,2,3,4,5,6,7,8]
})
max_spend_scale
#max_spend_scale.to_csv('max_spend_scale.csv',index=False)
# how find shop numeric scale
how_find_scale = pd.DataFrame({
'how_find':['','Walk in',
'Referral',
'Yelp',
'Google',
'Facebook',
'other'
],
'how_find_values':[0,1,2,3,4,5,6]
})
how_find_scale
#how_find_scale.to_csv('how_find_scale.csv',index=False)
# leave a review numeric scale
review_scale = pd.DataFrame({
'leave_review':['Yes','No','Sometimes'],
'review_values':[1,2,3]
})
#review_scale.to_csv('review_scale.csv',index=False)
In [8]:
gender_scale
Out[8]:
In [9]:
race_scale
Out[9]:
In [10]:
income_scale
Out[10]:
In [11]:
days_last_scale
Out[11]:
In [12]:
time_between_scale
Out[12]:
In [13]:
products_scale
Out[13]:
In [14]:
spend_scale
Out[14]:
In [15]:
max_spend_scale
Out[15]:
In [16]:
how_find_scale
Out[16]:
In [17]:
review_scale
Out[17]:
In [18]:
def numeric_survey(csv):
surveyimport = csv
# resave dataframe with relative columns
googledf = surveyimport[['What is your work zip code?','What is your home zip code?','Gender','Age','Race','Income','How long since your last haircut?','How long between typical haircuts?','Did you buy any products after your haircut?','How much did you spend on your haircut?','What is the most you would spend on a haircut?','How did you find your current barber?','Do you leave reviews on Yelp, Google, Etc? ','How important is Price ( 1 = not important, 5 = very important)','How important is Convenience( 1 = not important, 5 = very important)','How important is Atmosphere( 1 = not important, 5 = very important)','How important are Additional Services ( 1 = not important, 5 = very important)']]
# rename columns to match numeric scale legends keys
googledf.columns = ['work_zip','home_zip','gender','age','race','income','days_last_haircut','time_between_haircut','products','did_spend','max_spend','how_find','leave_review','price','convenient','atmosphere','amenities']
# merge legend tables with current dataframe to have all items in numeric terms for prediction model
legendDF = googledf.merge(gender_scale, on='gender',how='left')
legendDF2 = legendDF.merge(race_scale, on='race',how='left')
legendDF3 = legendDF2.merge(income_scale, on='income', how='left')
legendDF4 = legendDF3.merge(days_last_scale, on='days_last_haircut',how='left')
legendDF5 = legendDF4.merge(time_between_scale, on='time_between_haircut',how='left')
legendDF6 = legendDF5.merge(products_scale, on='products',how='left')
legendDF7 = legendDF6.merge(spend_scale, on='did_spend',how='left')
legendDF8 = legendDF7.merge(max_spend_scale, on='max_spend',how='left')
legendDF9 = legendDF8.merge(how_find_scale, on='how_find',how='left')
legendDF_final = legendDF9.merge(review_scale, on='leave_review',how='left')
# create dataframe with numeric scale values
legendDF_values = legendDF_final[['work_zip','home_zip','gender_values','age','race_values','income_values','days_last_values','time_between_values','products_values','spend_values','max_spend_values','how_find_values','review_values','price','convenient','atmosphere','amenities']]
# fill nan values with 0 for the scale/legend on non-legend responses
surveyFinal = legendDF_values.fillna(0)
# import time dependency fro today's date timestamp
import datetime as dt
date = dt.datetime.today().strftime("%m%d%Y")
surveyFinal.to_csv(f'../data/survey{date}.csv', index=False)
return surveyFinal.head()
In [19]:
numeric_survey(googlecsv)
Out[19]: